Data PreProcessing
Notebook 4 Pre-Processing the data.
Data preprocessing is a crucial step for any data analysis problem. It is often a very good idea to prepare your data in such way to best expose the structure of the problem to the machine learning algorithms that you intend to use. This involves a number of activities such as:
- Assigning numerical values to categorical data;
- Handling missing values;
- Normalizing the features (so that features on small scales do not dominate when fitting a model to the data).
In Exploratory Data Analysis, I explored the data, to help gain insight on the distribution of the data as well as how the attributes correlate to each other. I identified some features of interest. In this notebook I use feature selection to reduce high-dimension data, feature extraction and transformation for dimensional reduction.
Goal
Find the most predictive features of the data and filter it so it will enhance the predictive power of the analytics model.
Loading data and essential libraries
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from scipy.stats import norm
# visualization
import seaborn as sns
plt.style.use('fivethirtyeight')
sns.set_style("white")
plt.rcParams['figure.figsize'] = (8,4)
#plt.rcParams['axes.titlesize'] = 'large'
Importing data
data_df = pd.read_table('./dataset/MergeData.tsv', sep="\t", index_col=0)
data = data_df.reset_index(drop=True)
data.head()
Label encoding
Here, I assign the features to a NumPy array X, and transform the class labels from their original string representation (CRC and healthy) into integers
array = data.values
X_temp = array[:, 1:data.shape[1]]
y = array[:, 0]
array
array([['healthy', 46509517, 8249892, ..., 0, 0, 0],
['healthy', 5334509, 230275, ..., 0, 0, 0],
['healthy', 6868169, 4054008, ..., 0, 0, 0],
...,
['healthy', 0, 0, ..., 0, 0, 0],
['healthy', 2286204, 242316, ..., 630160, 653, 191409],
['healthy', 0, 0, ..., 0, 0, 0]], dtype=object)
centered log-ratio (clr) transformation
Transforms compositions from Aitchison geometry to the real space (skbio.stats.composition.clr).
from skbio.stats.composition import clr
pseude_value = np.amin(np.array(X_temp)[X_temp != np.amin(X_temp)])
data_temp = data.iloc[:, 1:data.shape[1]].T
data_clr = data_temp.apply(lambda x: clr(x + pseude_value), axis=0).T
X = data_clr.values[:, 0:data_clr.shape[1]]
X
array([[10.26214602, 8.53269436, 7.7298392 , ..., -3.44177889,
-3.44177889, -3.44177889],
[ 7.60933349, 4.46687166, 6.65482253, ..., -3.92913994,
-3.92913994, -3.92913994],
[ 8.41126745, 7.88408118, 7.66846676, ..., -3.37990451,
-3.37990451, -3.37990451],
...,
[-1.88844976, -1.88844976, 6.09721786, ..., -1.88844976,
-1.88844976, -1.88844976],
[ 7.74550107, 5.50128747, 7.86826035, ..., 6.45688651,
-0.33872724, 5.26551437],
[-1.22443516, -1.22443516, -1.22443516, ..., -1.22443516,
-1.22443516, -1.22443516]])
- transform the class labels from their original string representation (CRC and healthy) into integers
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
#Call the transform method of LabelEncorder on two dummy variables
#le.transform (['CRC', 'healthy'])
y
array([1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1,
0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0,
1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0,
1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0,
1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0,
0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0,
1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0,
1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1,
1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0,
0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1,
0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1,
0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1,
1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 0, 1,
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0,
0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
After encoding the class labels(disease) in an array y, the Responsed patients are now represented as class 1(i.e prescence of Response) and the Non-Responsed patients are represented as class 0 (i.e healthy), respectively, illustrated by calling the transform method of LabelEncorder on two dummy variables.
Assesing Model Accuracy: Split data into training and test sets
The simplest method to evaluate the performance of a machine learning algorithm is to use different training and testing datasets. Here I will
- Split the available data into a training set and a testing set. (70% training, 30% test)
- Train the algorithm on the first part,
- make predictions on the second part and
- evaluate the predictions against the expected results.
The size of the split can depend on the size and specifics of your dataset, although it is common to use 67% of the data for training and the remaining 33% for testing.
from sklearn.model_selection import train_test_split
##Split data set in train 70% and test 30%
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=7)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
((352, 151), (352,), (152, 151), (152,))
Feature Standardization
Standardization is a useful technique to transform attributes with a Gaussian distribution and differing means and standard deviations to a standard Gaussian distribution with a mean of 0 and a standard deviation of 1.
As seen in Exploratory Data Analysis the raw data has differing distributions (left skew distributions) which may have an impact on the most ML algorithms. Most machine learning and optimization algorithms behave much better if features are on the same scale.
Let’s evaluate the same algorithms with a standardized copy of the dataset. Here, I use sklearn to scale and transform the data such that each attribute has a mean value of zero and a standard deviation of one.
from sklearn.preprocessing import StandardScaler
# Normalize the data (center around 0 and scale to remove the variance).
scaler = StandardScaler()
Xs = scaler.fit_transform(X)
Feature decomposition using Principal Component Analysis (PCA)
From the pair plot in Exploratory Data Analysis, lots of feature pairs divide nicely the data to a similar extent, therefore, it makes sense to use one of the dimensional reduction methods to try to use as many features as possible and maintain as much information as possible when working with only 2 dimensions.
from sklearn.decomposition import PCA
# feature extraction
pca = PCA(n_components=10)
fit = pca.fit(Xs)
# summarize components
print("Explained Variance: %s" % fit.explained_variance_ratio_)
Explained Variance: [0.12475653 0.07725227 0.0362945 0.03049992 0.02403753 0.01906391
0.01846672 0.01726657 0.01640619 0.01474633]
- PCA plot
X_pca = pca.transform(Xs)
PCA_df = pd.DataFrame()
PCA_df['PCA_1'] = X_pca[:, 0]
PCA_df['PCA_2'] = X_pca[:, 1]
plt.figure(figsize=(6, 6))
plt.plot(PCA_df['PCA_1'][data.disease == 'CRC'], PCA_df['PCA_2'][data.disease == 'CRC'], 'o', alpha = 0.7, color = 'r')
plt.plot(PCA_df['PCA_1'][data.disease == 'healthy'], PCA_df['PCA_2'][data.disease == 'healthy'], 'o', alpha = 0.7, color = 'b')
plt.xlabel('PCA_1')
plt.ylabel('PCA_2')
plt.legend(['CRC', 'healthy'])
plt.show()
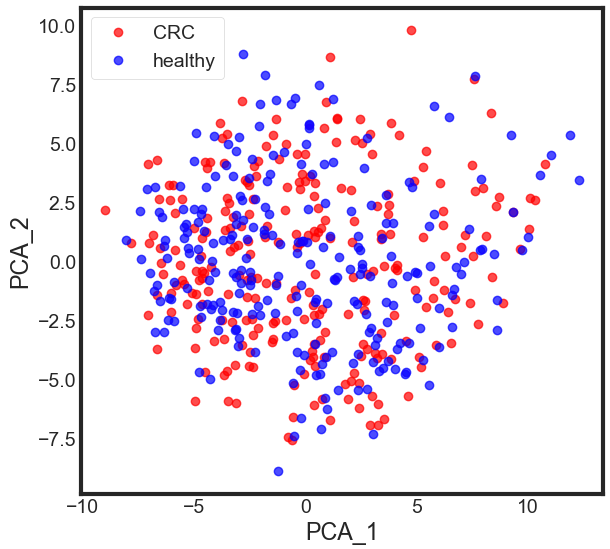
Now, what we got after applying the linear PCA transformation is a lower dimensional subspace (from 3D to 2D in this case), where the samples are “most spread” along the new feature axes.
- The amount of variance that each PC explains
#var= pca.explained_variance_ratio_
#Cumulative Variance explains
var1 = np.cumsum(np.round(pca.explained_variance_ratio_, decimals=4)*100)
print(var1)
[12.48 20.21 23.84 26.89 29.29 31.2 33.05 34.78 36.42 37.89]
Deciding How Many Principal Components to Retain
In order to decide how many principal components should be retained, it is common to summarise the results of a principal components analysis by making a scree plot. More about scree plot can be found here, and here
- The amount of variance that each PC explains
var = pca.explained_variance_ratio_
#Cumulative Variance explains
#var1=np.cumsum(np.round(pca.explained_variance_ratio_, decimals=4)*100)
#print(var1)
plt.plot(var)
plt.title('Scree Plot')
plt.xlabel('Principal Component')
plt.ylabel('Eigenvalue')
leg = plt.legend(['Eigenvalues from PCA'], loc='best', borderpad=0.3, shadow=False, markerscale=0.4)
leg.get_frame().set_alpha(0.4)
leg.set_draggable(state=True)
plt.show()
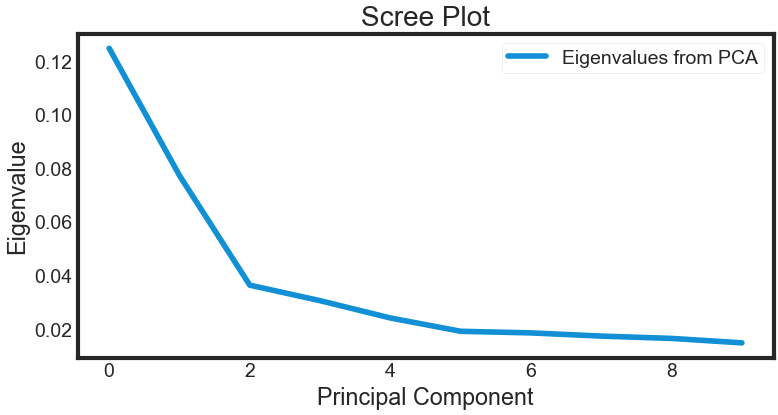
Static3Dplot
The most obvious change in slope in the scree plot occurs at component 3, which is the “elbow” of the scree plot. Therefore, it could be argued based on the basis of the scree plot that the first three components should be retained.
def Static3Dplot(reduced_data, labels, variable):
'''
draw a static compositional biplot in 3d for three principal components
Args:
reduced_data: data processed by PCA
labels: labels of the original dataset
variable: the names of the variables of the data set
'''
fig = plt.figure(figsize=(14, 10))
ax = plt.axes(projection='3d')
legend = []
classes = np.unique(labels)
n = reduced_data.shape[1]
colors = ['r', 'b']
x = reduced_data[:, 0]
y = reduced_data[:, 1]
z = reduced_data[:, 2]
scalex = 1.0/(x.max() - x.min())
scaley = 1.0/(y.max() - y.min())
scalez = 1.0/(z.max() - z.min())
# Scatter plot with a two-dimensional plot using normal PCA
for i, label in enumerate(classes):
ax.scatter3D(x[labels==label] * scalex,
y[labels==label] * scaley,
z[labels==label] * scalez,
linewidth=0.01,
c=colors[i])
legend.append("Group: {}".format(label))
ax.legend(legend)
# the initial angle to draw the 3d plot
azim = -60
elev = 30
ax.view_init(elev, azim)
# plot arrows as the variable contribution, each variable has a score for PCA1 and PCA2 respectively
for i in range(n):
ax.quiver(0, 0, 0, reduced_data[0, i], reduced_data[1, i], reduced_data[2, i], color='k', alpha=0.7, linewidth=1, arrow_length_ratio=0.05)
ax.text(reduced_data[0, i]*1.1, reduced_data[1, i]*1.1, reduced_data[2, i]*1.1, variable[i], ha='center', va='center', color='k', fontsize=12)
ax.set_xlabel('PCA1')
ax.set_ylabel('PCA2')
ax.set_zlabel('PCA3')
plt.title('Compositional Plot in 3 Dimension')
plt.grid()
plt.show()
Static3Dplot(X_pca, data.disease, data.columns[1:data.shape[1]])
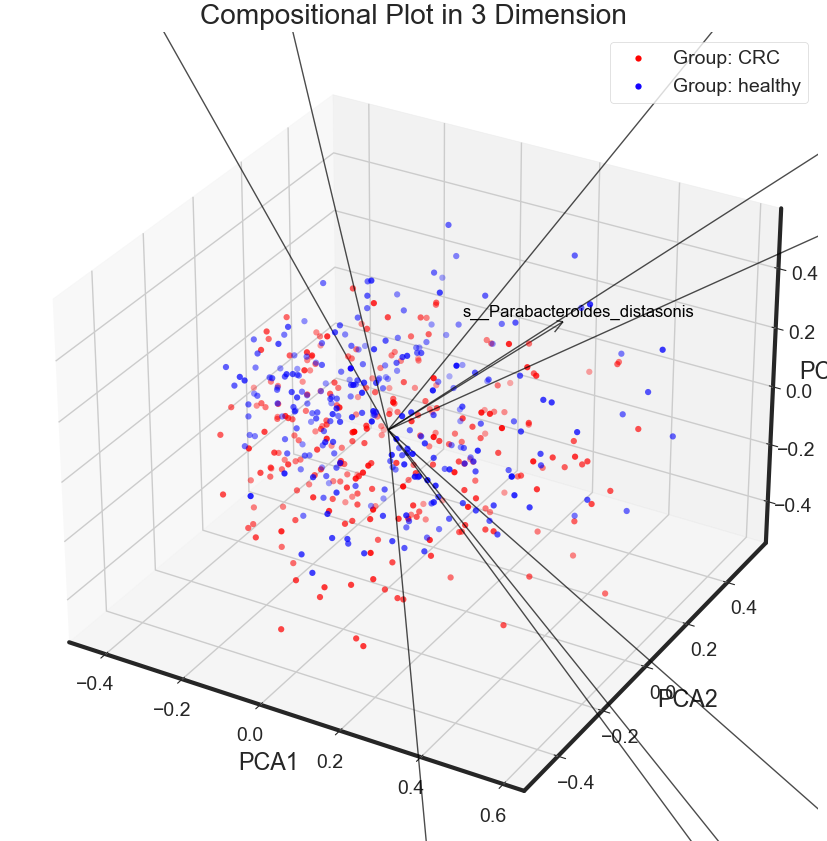
Compositional biplot
import numpy as np
from sklearn.decomposition import PCA
def biplotPCA(reduced_data, labels, variable):
'''
plot compositional biplot for two principal components
Args:
reduced_data: data processed by PCA
labels: labels of the original dataset
variable: the names of the variables of the data set
'''
plt.figure(figsize=(12, 8))
legend = []
classes = np.unique(labels)
n = reduced_data.shape[1]
colors = ['r', 'b']
x = reduced_data[:, 0]
y = reduced_data[:, 1]
scalex = 1.0/(x.max() - x.min())
scaley = 1.0/(y.max() - y.min())
# Scatter plot with a two-dimensional plot using normal PCA
for i, label in enumerate(classes):
plt.scatter(x[labels==label] * scalex,
y[labels==label] * scaley,
linewidth=0.01,
c=colors[i])
legend.append("Group: {}".format(label))
plt.legend(legend)
# plot arrows as the variable contribution, each variable has a score for PCA1 and PCA2 respectively
for i in range(n):
plt.arrow(0, 0, reduced_data[0, i], reduced_data[1, i], color='k', alpha=0.7, linewidth=1)
plt.text(reduced_data[0, i]*1.01, reduced_data[1, i]*1.01, variable[i], ha='center', va='center', color='k', fontsize=12)
plt.xlabel('PCA1')
plt.ylabel('PCA2')
plt.title('Compositional biplot')
plt.grid()
plt.show()
biplotPCA(X_pca, data.disease, data.columns[1:data.shape[1]])
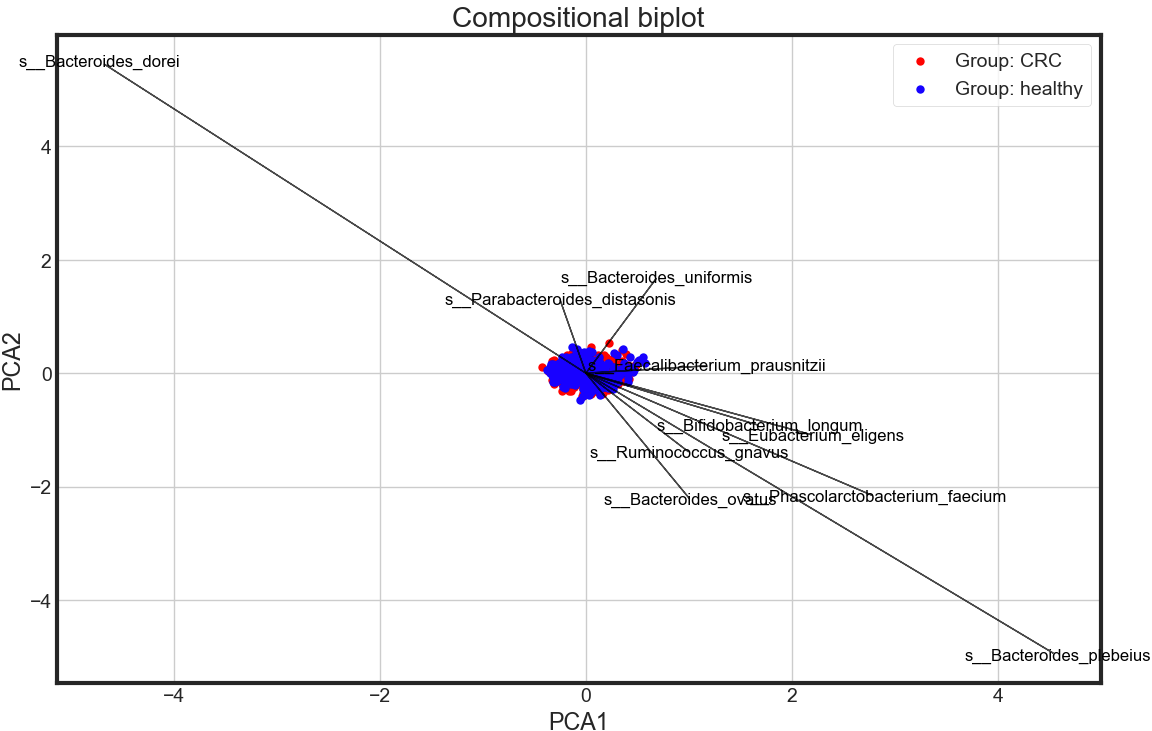
Observation
- PCA shows no significant differneces between CRC and healthy in the whole gut microbial species level
Output
Saving the transformed and noramlized profile
prof = pd.DataFrame(X)
prof.columns = data.columns[1:data.shape[1]]
prof.index = data_df.index
phen = data.loc[:, 'disease']
phen.index = data_df.index
mdat = pd.merge(phen, prof, on="SampleID", how="inner")
mdat.to_csv('./dataset/MergeData_clr.tsv',
sep='\t', encoding='utf-8', index=True)
mdat.head()
A Summary of the Data Preprocing Approach used here:
assign features to a NumPy array X, and transform the class labels from their original string representation (CRC and healthy) into integers
transform compositional data into Gaussian space
Split data into training and test sets
Standardize the data.
Obtain the Eigenvectors and Eigenvalues from the covariance matrix or correlation matrix
Sort eigenvalues in descending order and choose the kk eigenvectors that correspond to the kk largest eigenvalues where k is the number of dimensions of the new feature subspace (k≤dk≤d).
Construct the projection matrix W from the selected k eigenvectors.
Transform the original dataset X via W to obtain a k-dimensional feature subspace Y.
Visualise the PCA results via compositional plot and 3 dimensional plot.
It is common to select a subset of features that have the largest correlation with the class labels. The effect of feature selection must be assessed within a complete modeling pipeline in order to give you an unbiased estimated of your model’s true performance. Hence, in the next section you will first be introduced to cross-validation, before applying the PCA-based feature selection strategy in the model building pipeline.